Independent scholar at Max Planck Institute for the Science of Human History
– ← Back to cvTechnologies
Table of contents
In this position I continued my work on the Sound-Comparisons project.
In addition to it a new project by the name of IE-CoR (previously named CoBL and ielex2) came into focus.
TL;DR
I did contract work for different research projects to support teams with data-entry, collaboration, presentation and plumbing between different tools.
To do so I made use of Python, JavaScript, PHP and Java. Data was frequently kept in PostgreSQL or MariaDB instances. Deployments were handled both manually and using Docker.
IE-CoR
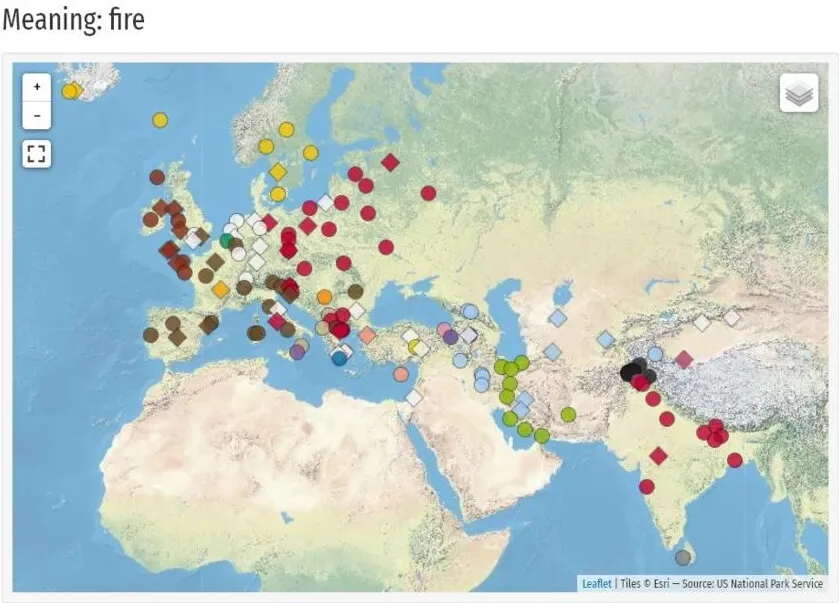
I’d say one of ideas behind this project was to collect cognate relationships for some vocabulary so that later research can use it for phylogenetic analysis.
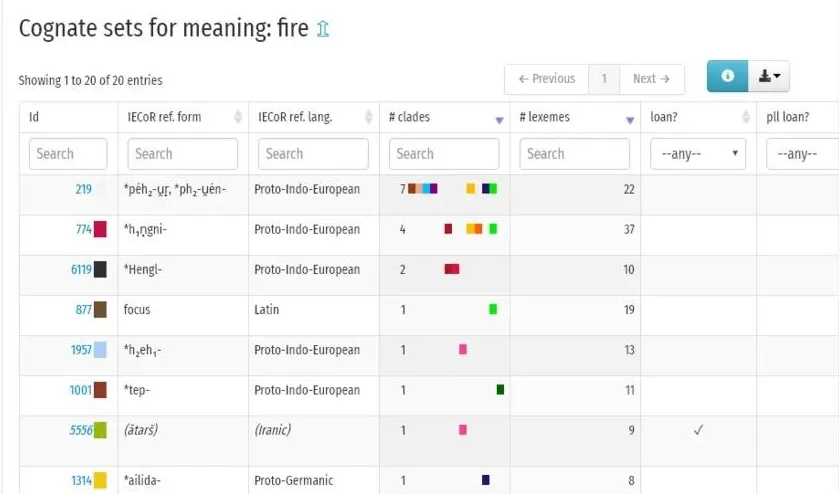
More bluntly I’d say the idea was to support researchers in entering similarity data between words as well as some data on when these words were likely used so that they can later compute likely evolution graphs for languages.
Some tasks in scope of this project were:
- Quickly familiarize myself with the python codebase as well as coming up with deployment and backup strategies to get it ready to use for the research team.
- Iterate on the teams needs for data-entry and presentation.
- Maintain and expand support for the Nexus file format.
a paper was published in nature scientific data, and I’m happy to count myself among the contributors to it. Similarly you can find me in iecor.clld.org/contributors.
As described on the Max Planck project page the research also led to a paper published in science.
I feel grateful for the opportunity to play a supportive role as an independent scholar here, for the chance to contribute a small share in improving and building software to structure, capture and edit data, and for the memorable time spent with all the kind people on this project.
Sound-Comparisons
I continued to take care of the Sound-Comparisons codebase with several new features and bug fixes.
Project description
A detailed description of this project is made with Sound Comparisons: A New Resource for Exploring Phonetic Diversity across Language Families of the World. More information is available in this presentation (pdf) or at the project page [pdf].
To simplify I’d say the project makes use of a Swadesh list to compare different languages. Researchers then collect field data on these (endangered) languages from native speakers and carefully document their findings. Afterwards this data can be used for exploration or to measure divergence in phonetics between related languages, dialects and accents.
It was my pleasure to provide technical support to this project and build features as required for linguistic research.
Offline deployments
A new feature that struck me as particularly interesting was get the Sound-Comparisons website ready for offline deployments. The motivation behind this was to support fieldwork in remote areas.

Offline deployments meant that the website would be accessed via file:// and be shipped on USB sticks.
It was particular fun to render select areas of maps into files to keep the map features working as intended.